
Canada Builds Live SARS-CoV-2 Viruses From Computer Code Alone That ‘Can Be Used For Gain-of-Function Research’: Journal ‘Viruses’
A closed pandemic loop of digital design, synthetic GOF viruses, and government-controlled verification.

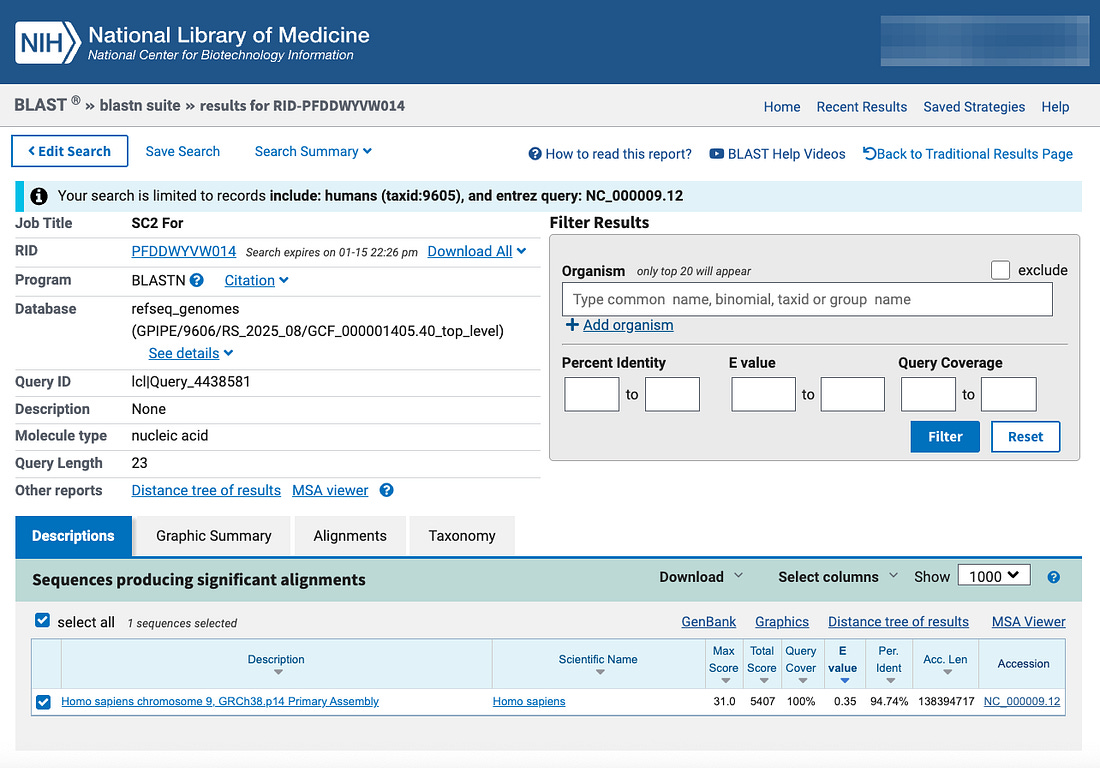
A new peer-reviewed study published in the journal Viruses says that publicly funded Canadian laboratories digitally designed full-length SARS-CoV-2 genomes, chemically synthesized them using commercial services, and generated live, replication-competent coronaviruses without starting from a natural virus sample.
The paper, titled “Developing Synthetic Full-Length SARS-CoV-2 cDNAs and Reporter Viruses for High-Throughput Antiviral Drug Screening,” documents the alleged creation of infectious Delta and Omicron SARS-CoV-2 viruses from computer-designed genetic sequences alone.
Coming in the wake of the COVID-19 pandemic—which killed millions of people worldwide and was linked by multiple intelligence agencies to laboratory research—the study raises national security concerns about the ability of government-funded institutions to create replication-competent pandemic viruses from digital sequence data alone, using commercial infrastructure with limited public oversight.
In light of these capabilities, the study also raises the possibility that governments could define, simulate, and respond to a biological threat almost entirely within digital and laboratory frameworks—leaving the public reliant on official interpretation rather than independently observable evidence.

Viruses Built from Computer Code Alone
The authors state that they did not rely on physical viral isolates to create the viruses.
Instead, they used commercial DNA synthesis services to generate the entire coronavirus genome:
“We opted to use cDNA chemical synthesis services to generate full-length wild-type and reporter Delta and Omicron clones.”
They further explain:
“DNA synthesis is a viable method to rapidly generate coronavirus cDNAs and recombinant viruses.”
Those synthesized genomes were then said to be used to generate live viruses:
“Clone-derived Delta and Omicron wild-type and reporter viruses were successfully rescued and showed replication kinetics comparable to patient-derived isolates.”
The study claims that the resulting viruses were infectious and capable of sustained replication in cell culture.
The paper emphasizes that the same system can be used to generate new viral variants based solely on sequence data:
“DNA synthesis is a viable and rapid option to generate reverse genetic systems for wild-type and reporter viruses using sequence information alone.”
Acknowledged Gain-of-Function Capability
In the Discussion section, the authors explicitly acknowledge that the methodology they used qualifies as gain-of-function (GOF) capable research:
“It is important to acknowledge that the novel approach described in this study—generating replication-competent viruses from synthetic DNA while introducing heterogeneous gene functions—can be used for ‘gain-of-function’ research.”
Where the Viruses Were Said to Be Created
All work involving purportedly live SARS-CoV-2 was conducted in Canada at a high-containment facility:
“All the experiments involving infectious SARS-CoV-2 viruses were conducted at VIDO-InterVac in an approved Biosafety containment level 3 (BSL3) laboratory.”
VIDO-InterVac is part of the University of Saskatchewan, which is a central institutional hub for the research described in the paper.
Author Affiliations
The authors are affiliated with multiple Canadian institutions, including:
- University of Saskatchewan (Department of Biochemistry, Microbiology, and Immunology; Vaccine and Infectious Disease Organization),
- University of Alberta (Department of Cell Biology; Department of Medical Microbiology & Immunology; Li Ka Shing Institute of Virology),
- Sunnybrook Research Institute (Toronto),
- University of Toronto (Department of Laboratory Medicine and Pathobiology).
Public Funding Sources
The research was funded entirely through public Canadian funding, according to the paper’s funding disclosure:
“This research was funded by the Canadian Institutes of Health Research (CIHR)-funded Coronavirus Variants Rapid Response Network (CoVaRR-Net)… CIHR Operating COVID-19 Rapid Research Funding Opportunity—Therapeutics… and NSERC.”
Additional operational support came from:
“The Government of Saskatchewan… the Government of Canada through Prairies Economic Development Canada… and the Canada Foundation for Innovation Major Science Initiatives for its CL3 facility.”
What the Paper Establishes
The study documents, in the authors’ words, that:
- Full-length SARS-CoV-2 genomes were digitally designed
- Those genomes were chemically synthesized
- Live, replication-competent coronaviruses were said to be generated from that synthetic DNA
- The method is acknowledged to be usable for gain-of-function research
- The work was publicly funded and conducted in Canadian government-supported laboratories
These facts are stated directly in the paper and do not rely on inference, speculation, or external interpretation.
Bottom Line
The new Viruses paper reveals that governments claim to possess the technical ability to define a virus digitally, synthesize it physically, and validate its behavior entirely within controlled laboratory systems—allowing modern pandemic response to operate almost entirely inside digital, synthetic, and laboratory environments.
That convergence raises unresolved questions about national security, transparency, independent verification, and how much trust the public is asked to place in closed scientific and governmental frameworks when responding to future biological threats.
The study aligns with earlier FOIA-released DARPA documents showing that U.S. biodefense systems were already built to synthesize viruses and manufacture mRNA countermeasures from sequence data alone, placing the Canadian work within a broader pre-existing digital pandemic infrastructure.





































Recent Comments